Using Globus on SubMIT¶
Globus is a powerful platform for fast, secure, and reliable data transfer between research computing systems. On the SubMIT cluster, we have set up a Globus endpoint, allowing you to move data between your local machine, cloud storage, and SubMIT with ease.
Note
You will need a Globus account to get started. You can register and log in using your MIT credential.
You can watch a video presentation on Globus by a member of the SubMIT team.
What is Globus?¶
Globus is a web-based service designed for transferring and sharing large datasets. It supports:
High-speed, fault-tolerant transfers
Direct transfers between endpoints (e.g., SubMIT ⇄ personal computer)
Sharing data with collaborators
Managing access permissions securely
The documentation of Globus is at https://docs.globus.org/
Setting up Globus¶
Log in to Globus:
Go to https://www.globus.org/ and click “Log In” using your MIT credential.
Search for the SubMIT Endpoint:
After logging in, go to the File Manager tab. In one of the search boxes, type
SubMITto find the endpoint for our cluster.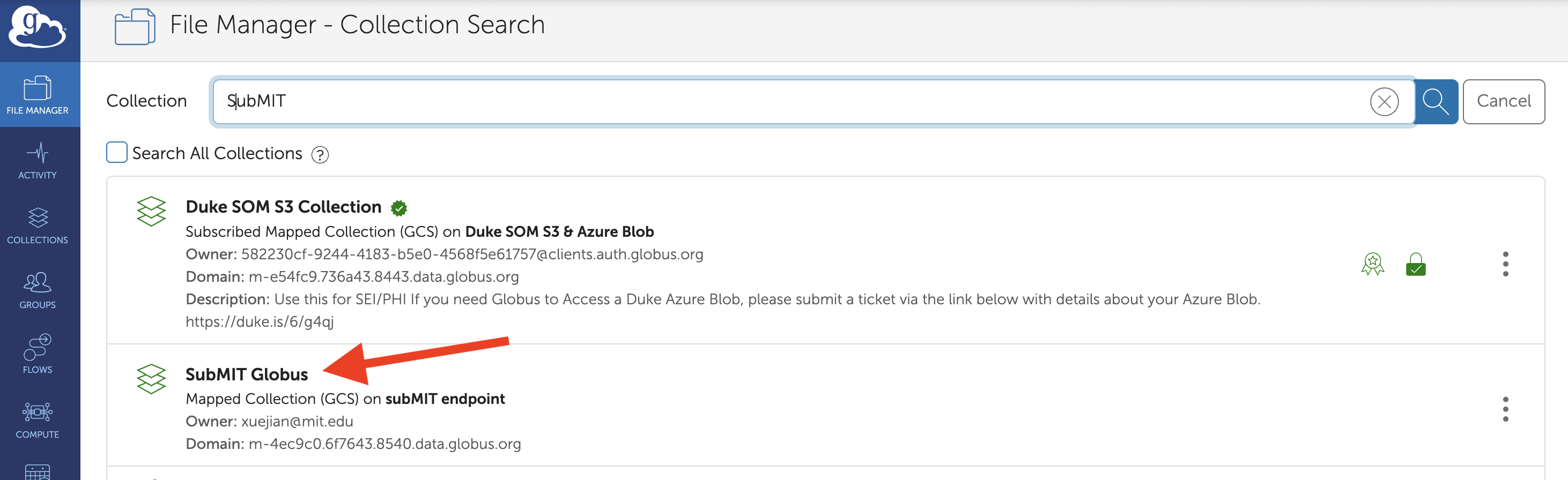
Authenticate to the SubMIT Endpoint:
Click on the SubMIT endpoint and authenticate with your MIT credential when prompted.
Transferring Files¶
Select Source and Destination:
In the File Manager, open two panels: - One for your local machine (via Globus Connect Personal or another endpoint) - One for SubMIT
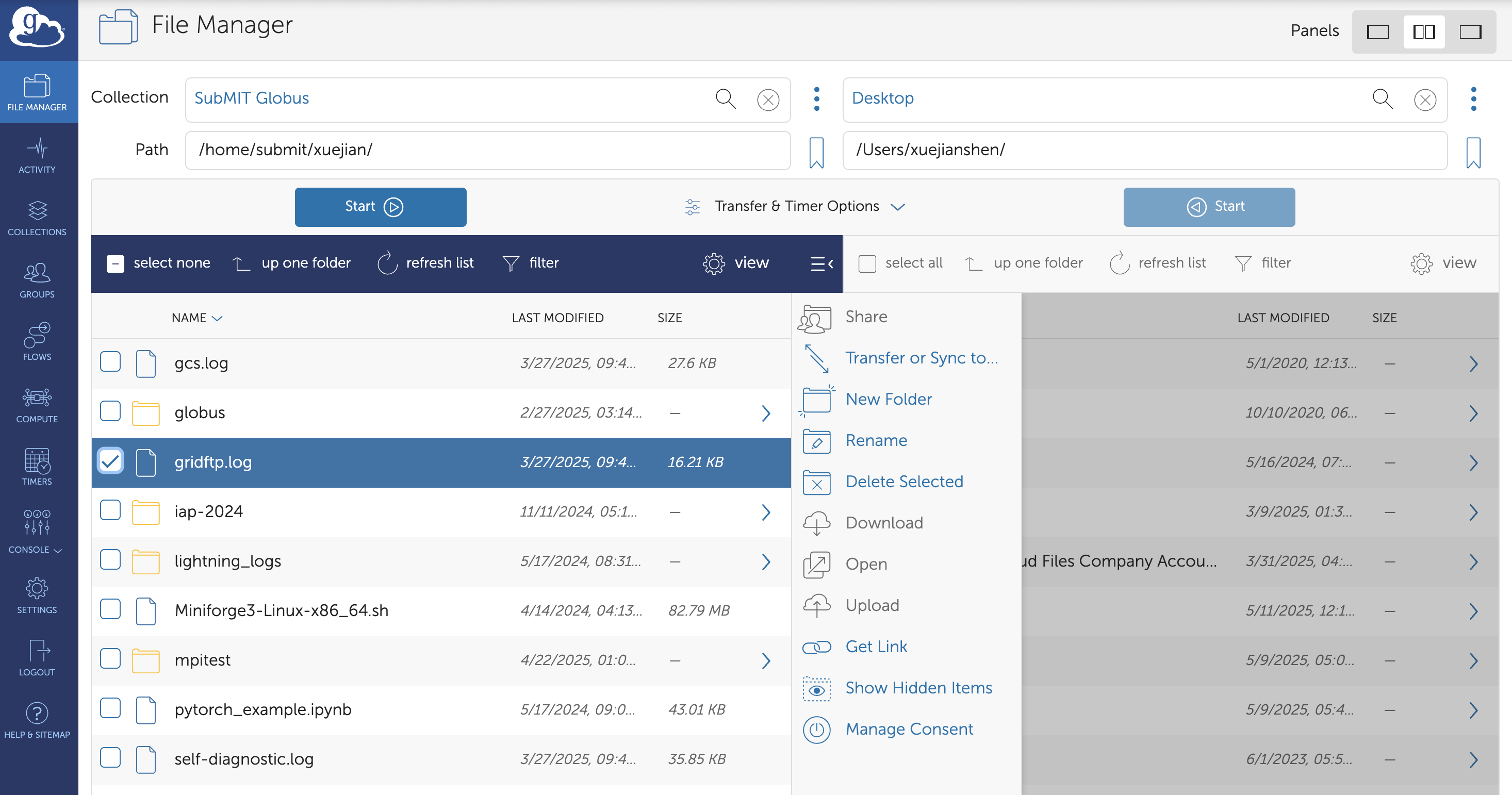
Browse and Select Files:
Navigate to the desired directories and select files or folders to transfer.
Click “Start” to Begin the Transfer:
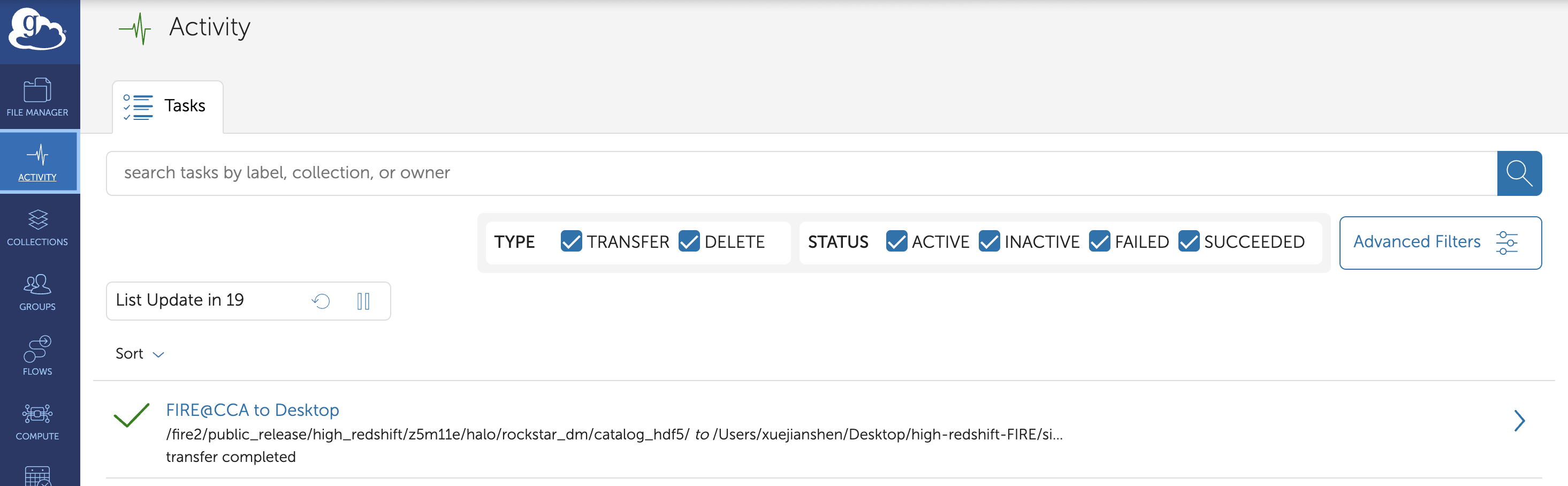
Globus will handle the rest. It ensures reliability even if the connection drops, and you can monitor transfer progress in the Activity tab.
Using Globus Connect Personal¶
To transfer data to/from your personal laptop or workstation, you need to install Globus Connect Personal:
Download it from: https://www.globus.org/globus-connect-personal
Install and log in with your Globus ID (linked with your MIT credential)
Set up a local endpoint and give it a name (e.g., “My Laptop”)
Once running, your machine will appear as an endpoint in the File Manager.
Tips and Best Practices¶
Use Globus for transferring large datasets, rather than scp or rsync.
If a transfer fails, you can restart it from where it left off.
Transfers happen asynchronously - you do not need to stay logged in.
You can receive email notifications for completed or failed transfers.